正常来说,博客的开头都会放参考文章地址的
但是这一篇文章不一样,是根据通义千问的答案整理的……
所以只好感谢通义千问对本文的大力支持了,O(∩_∩)O哈哈~
初始化表
假设有一张部门表,其结构如下:
CREATE TABLE public.tb_dept (
dept_id int8 NOT NULL, -- 部门ID
dept_name varchar NULL, -- 部门名称
parent_id int8 NULL, -- 父部门ID
path_id varchar NULL, -- ID层级
path_name varchar NULL, -- 名称层级
CONSTRAINT tb_dept_pk PRIMARY KEY (dept_id)
);
COMMENT ON TABLE public.tb_dept IS '部门表';
COMMENT ON COLUMN public.tb_dept.dept_id IS '部门ID';
COMMENT ON COLUMN public.tb_dept.dept_name IS '部门名称';
COMMENT ON COLUMN public.tb_dept.parent_id IS '父部门ID';
COMMENT ON COLUMN public.tb_dept.path_id IS 'ID层级';
COMMENT ON COLUMN public.tb_dept.path_name IS '名称层级';
初始化数据如下:
INSERT INTO public.tb_dept (dept_id, dept_name, parent_id, path_id, path_name) VALUES(1, '总公司', 0, NULL, NULL);
INSERT INTO public.tb_dept (dept_id, dept_name, parent_id, path_id, path_name) VALUES(2, '财务部', 1, NULL, NULL);
INSERT INTO public.tb_dept (dept_id, dept_name, parent_id, path_id, path_name) VALUES(3, '会计部', 2, NULL, NULL);
INSERT INTO public.tb_dept (dept_id, dept_name, parent_id, path_id, path_name) VALUES(4, '出纳部', 2, NULL, NULL);
INSERT INTO public.tb_dept (dept_id, dept_name, parent_id, path_id, path_name) VALUES(5, '研发部', 1, NULL, NULL);
INSERT INTO public.tb_dept (dept_id, dept_name, parent_id, path_id, path_name) VALUES(6, 'PHP开发部', 5, NULL, NULL);
INSERT INTO public.tb_dept (dept_id, dept_name, parent_id, path_id, path_name) VALUES(7, 'Java开发部', 5, NULL, NULL);
INSERT INTO public.tb_dept (dept_id, dept_name, parent_id, path_id, path_name) VALUES(8, '测试部', 5, NULL, NULL);
INSERT INTO public.tb_dept (dept_id, dept_name, parent_id, path_id, path_name) VALUES(9, '测试部一组', 8, NULL, NULL);
INSERT INTO public.tb_dept (dept_id, dept_name, parent_id, path_id, path_name) VALUES(10, '测试部二组', 8, NULL, NULL);
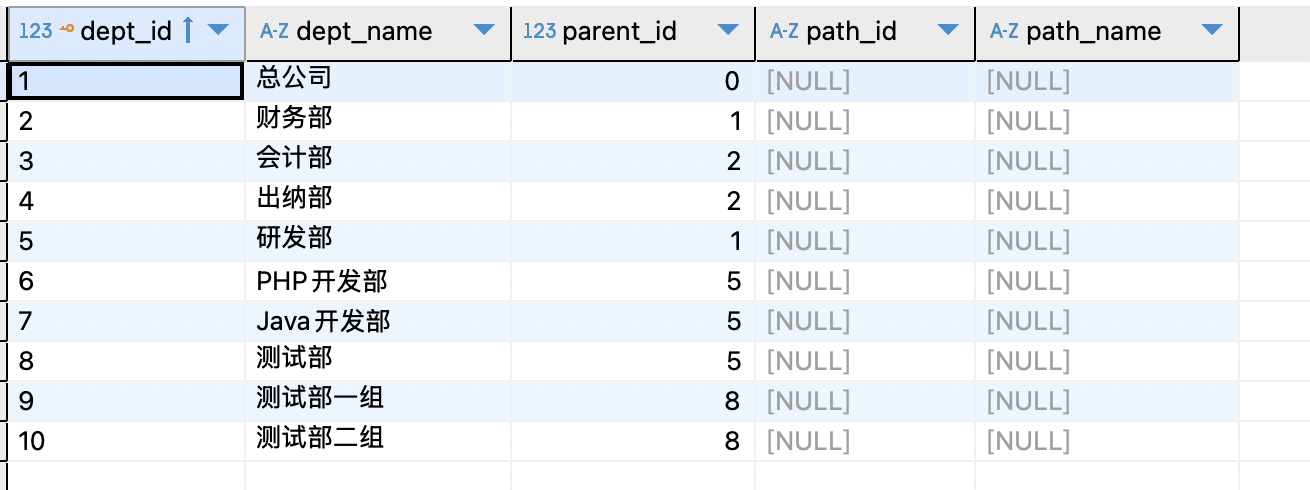
根据父ID组合数据
要求:将部门ID以及其各级父部门的ID按照层级拼接并用中横线-间隔,将各级部门名称用@符号间隔
WITH RECURSIVE dept_hierarchy AS (
-- 基础情况:选择所有顶级部门(parent_id = 0)
SELECT
dept_id,
dept_name,
CAST(dept_id AS TEXT) AS path_id,
CAST(dept_name AS TEXT) AS path_name
FROM tb_dept
WHERE parent_id = 0
UNION ALL
-- 递归部分:选择子部门并将其附加到父部门路径上
SELECT
d.dept_id,
d.dept_name,
dh.path_id || '-' || d.dept_id,
dh.path_name || '@' || d.dept_name
FROM tb_dept d
JOIN dept_hierarchy dh ON d.parent_id = dh.dept_id
)
UPDATE tb_dept d
SET path_id = dh.path_id,path_name = dh.path_name
FROM dept_hierarchy dh
WHERE d.dept_id = dh.dept_id;
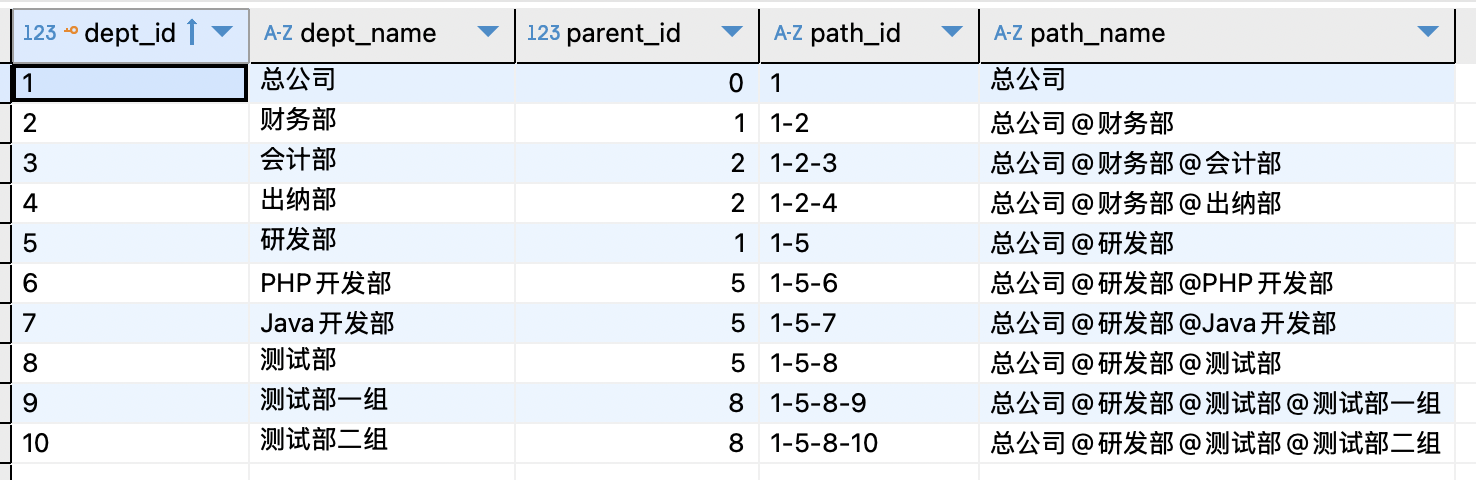
根据ID层级组合数据
要求:将部门ID层级根据中横线-切分,然后用切分后的ID关联名称,再将名称根据ID顺序拼接起来并用@符号间隔
先将上一小节生成的path_name列置空:
update tb_dept set path_name = null;
再用下列SQL重新生成:
WITH
split_path AS (
SELECT
r.dept_id AS record_id,
s.value::bigint AS item_id,
s.ordinality AS pos
FROM tb_dept r
CROSS JOIN LATERAL unnest(string_to_array(r.path_id, '-')) WITH ORDINALITY AS s(value)
),
join_name AS (
SELECT
sp.record_id,
i.dept_name,
sp.pos
FROM split_path sp
JOIN tb_dept i ON sp.item_id = i.dept_id
),
agg_name as(
SELECT
r.dept_id AS record_id,
r.path_id,
string_agg(jn.dept_name, '-' ORDER BY jn.pos) AS names
FROM tb_dept r
JOIN join_name jn ON r.dept_id = jn.record_id
GROUP BY r.dept_id, r.path_id
)
UPDATE tb_dept d
SET path_name = names
FROM agg_name
WHERE d.dept_id = agg_name.record_id;