参考这里
创建过程
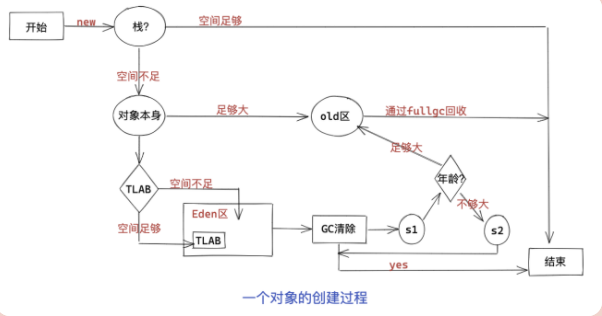
根据图示,逐步详解:
-
一个对象new出来时,先判断线程栈是否能分配下
- 如果能分配下,直接分配在栈中
- 如果分配不下则进行第二步
-
判断该对象是否足够大
- 如果足够大,则直接进入老年代
- 如果不够大,则进行第三步
-
判断创建对象的线程的TLAB(本地线程缓冲区)空间是否足够
- 如果足够,直接分配在TLAB中
- 如果不够,则进入Eden区中其他空间。然后进行第四步
-
GC清除
- 如果清除掉了该对象,则直接结束
- 如果没有清除掉对象,进行第5步
-
此刻对象进入Survivor 1 区,判断年龄是否足够大
- 如果年龄足够大,则直接进入old区域
- 如果年龄不够大,则进入Survivor 2 区,然后进入第4步,循环往复
问题解析
通过上图和步骤解析,大家应该对一个对象的创建过程有一个很清晰的概念了。
但是其中还是有很多小细节会被忽略,比如:
-
为什么对象会选择先分配在栈中?
首先栈是线程私有的,将对象优先分配在栈中,可以通过pop直接将对象的所有信息、空间直接清除,当线程消亡的时候也可以直接清理这一块儿TLAB区域。 -
为什么 JVM 会让大对象会直接进入老年代?
大对象需要连续的空间来存储,如果不存入老年代对jvm说就可能是一个负担,如果没有足够的空间就有可能导致提前触发gc来清理空间来安置大对象。 -
为什么会选择先进入TLAB?
TLAB是线程本地缓冲区,TLAB的好处就是防止不同线程创建对象选择同一块儿内存区域而产生竞争,会使其概率大大减少。 -
为什么会有两个Survivor区?并且存活且年龄不够大的对象会从一个Survivor区转到另一个Survivor区?
根据根可达算法,jvm会从开始寻找到所有正在使用的对象,没有使用的就是垃圾,通常情况下,很多对象都是用完就抛弃的,所以真正在Survivor区长时间存活的对象非常少,将这部分对象从一个Survivor区转到另一个Survivor区后,就可以直接对这个Survivor区进行全量的空间回收了,效率会很高。