读了这篇文章感觉对 Java GC 的理解透彻多了,所以就决定做个笔记
JVM 内存区域
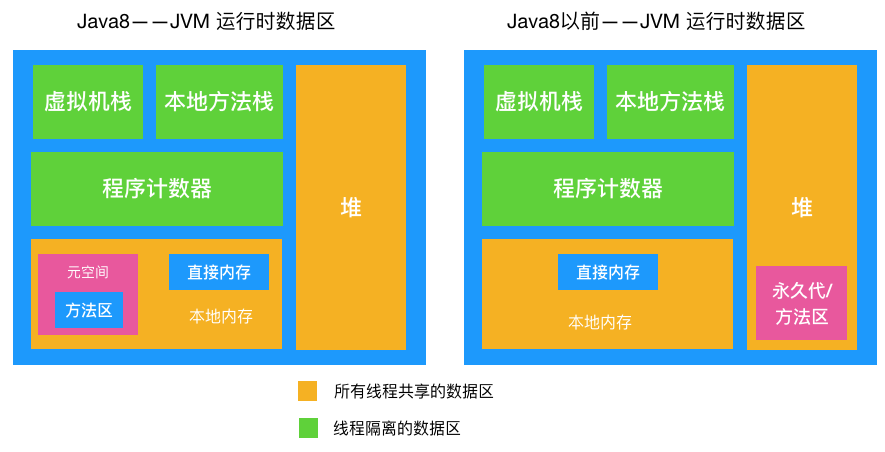
- 虚拟机栈、本地方法栈、程序计数器、Java 8 之后的本地内存不需要进行 GC
- 堆是 GC 发生的区域
垃圾识别方法
- 引用计数法:对象被引用一次,则在它的对象头加一次引用次数,如果没有引用(引用次数为 0), 则对象可回收。但其无法解决循环引用的问题,所以不采用。
- 可达性算法:从一系列叫做 GC Root 的对象为起点出发,引出它们指向的下一个节点,再以下个节点为起点,引出此节点指向的下一个结点,这样通过 GC Root 串成的一条线就叫引用链,直到所有的结点都遍历完毕。如果对象不在任意一个以 GC Root 为起点的引用链中,则会被判断为「垃圾」,会被 GC 回收。
哪些对象可以作为 GC Root 呢?
- 虚拟机栈(栈帧中的本地变量表)中引用的对象
- 本地方法栈中 JNI(即一般说的 Native 方法)引用的对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
垃圾回收方法
- 标记清除法:先根据可达性算法标记出相应的可回收对象,再对可回收的对象进行回收。会形成较多的内存碎片,基本不用。
- 标记整理法:前两步和标记清除法一样,但它在标记清除法的基础上添加了一个整理的过程,即将所有的存活对象都往一端移动,再清理掉另一端的所有区域,这样就解决了内存碎片的问题。问题在于:每次垃圾清除都要频繁地移动存活的对象,效率十分低下。
- 复制算法:将堆均分为 A 和 B;先在 A 分配对象,B 不分配;清理时将 A 存活的对象复制到 B,然后清空 A;下次将 B 存活的对象复制到 A,清空 B。问题有二:一是可用空间只有一半;二是大量复制对象,性能低下。
分代收集算法
分代收集算法整合了以上算法的优点,最大程度避免了它们的缺点,所以是现代虚拟机采用的首选算法。与其说它是算法,倒不是说它是一种策略,因为它是把上述几种算法整合在了一起。 分代收集算法的基础在于:大部分对象都很短命,会在很短的时间内被回收(IBM 专业研究表明,一般来说,98% 的对象都是朝生夕死的,经过一次 Minor GC 后就会被回收)。 分代收集算法根据对象存活周期的不同将堆分成新生代和老生代(Java8以前还有个永久代),默认比例为 1 : 2;新生代又分为 Eden 区, from Survivor 区(简称S0),to Survivor 区(简称 S1),三者的比例为 8: 1 : 1。这样就可以根据新老生代的特点选择最合适的垃圾回收算法。 我们把新生代发生的 GC 称为 Young GC(也叫 Minor GC),老年代发生的 GC 称为 Old GC(也称为 Full GC)。
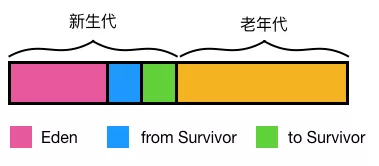
- 堆分为新生代和老生代(老年代),默认比例 1:2
- 新生代分为 Eden 区、from Survivor 区(S0)、to Survivor 区(S1),比例为 8:1:1
- 新生代的 GC 称为 Young GC(Minor GC),使用复制算法,因为在 Eden 区分配的对象大部分在 Minor GC 后都消亡了,只剩下极少部分存活对象,可以最大限度地降低复制算法造成的对象频繁拷贝带来的开销
- 老年代发生的 GC 称为 Old GC(Full GC),使用标记整理法
- S0 或 S1 中的存活对象每次 Minor GC 都可能被回收
- 对象的年龄即发生 Minor GC 的次数
YGC 的过程
- 对象一般分配在 Eden 区,当 Eden 区将满时,触发 Minor GC
- 经过 Minor GC 后只有少部分对象会存活,它们会被移到 S0 区,同时对象年龄加一,最后把 Eden 区对象全部清理以释放出空间
- 下一次 Minor GC 时,会把 Eden 区的存活对象和 S0 中的存活对象一起移到 S1,同时对象年龄加一,最后清空 Eden 和 S0 的空间
- 若再触发下一次 Minor GC,则重复上一步,只不过此时变成了从 Eden、S1 区将存活对象复制到 S0 区。每次垃圾回收,S0、S1 角色互换,都是从 Eden、S0(或S1) 将存活对象移动到 S1(或S0)
对象晋升
- 当对象的年龄达到了设定的阈值,则会从S0(或S1)晋升到老年代
- 当某个对象分配需要大量的连续内存时,此时对象的创建不会分配在 Eden 区,会直接分配在老年代
- 在 S0(或S1) 区相同年龄的对象大小之和大于 S0(或S1)空间一半以上时,则年龄大于等于该年龄的对象也会晋升到老年代
Stop The World
如果老年代满了,会触发 Full GC,Full GC 会同时回收新生代和老年代(即对整个堆进行GC),它会导致 Stop The World(简称 STW),造成挺大的性能开销。
什么是 STW ?所谓的 STW,即在 GC(minor GC 或 Full GC)期间,只有垃圾回收器线程在工作,其他工作线程则被挂起。
Safe Point
由于 Full GC(或 Minor GC)会影响性能,所以我们要在一个合适的时间点发起 GC,这个时间点被称为 Safe Point。
这个时间点的选定既不能太少以让 GC 时间太长导致程序过长时间卡顿,也不能过于频繁以至于过分增大运行时的负荷。
一般当线程在这个时间点上状态是可以确定的,如确定 GC Root 的信息等,可以使 JVM 开始安全地 GC。
Safe Point 主要指的是以下特定位置:
- 循环的末尾
- 方法返回前
- 调用方法的 call 之后
- 抛出异常的位置
垃圾收集器种类
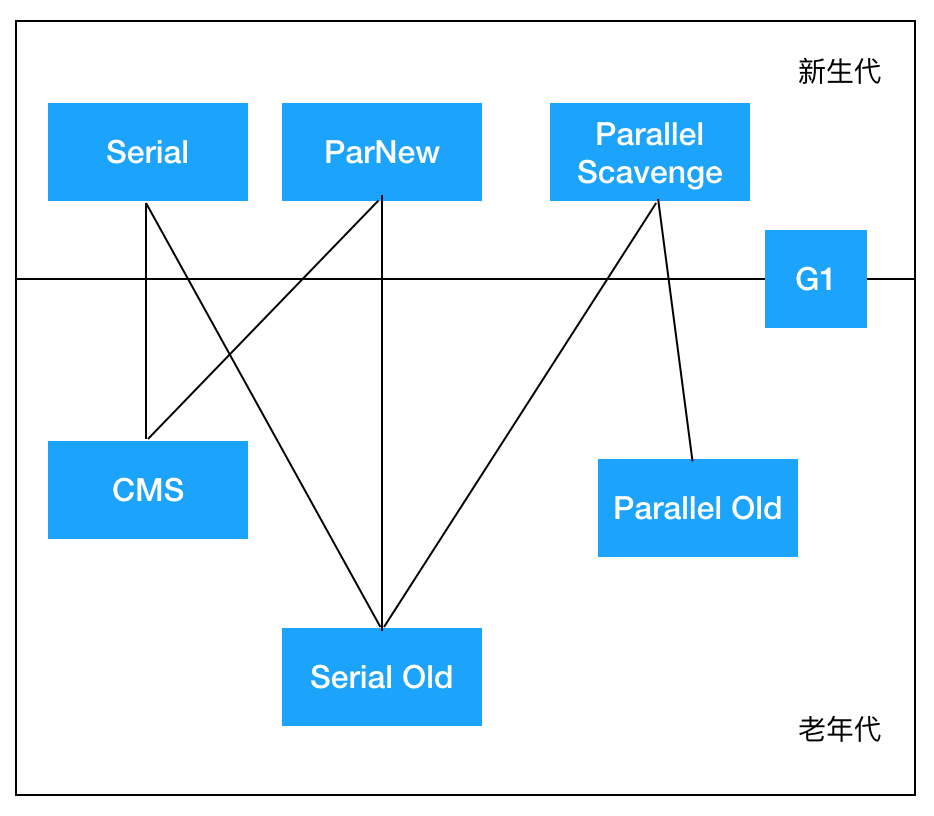
- 在新生代工作的垃圾回收器:Serial,ParNew,ParallelScavenge
- 在老年代工作的垃圾回收器:CMS,Serial Old,Parallel Old
- 同时在新老生代工作的垃圾回收器:G1
图片中的垃圾收集器如果存在连线,则代表它们之间可以配合使用
新生代收集器
- Serial 收集器是工作在新生代的、单线程的垃圾收集器,对于运行在 Client 模式下的虚拟机,Serial 收集器是新生代的默认收集器
- ParNew 收集器是 Serial 收集器的多线程版本,主要工作在 Server 模式,是许多运行在 Server 模式下的虚拟机的首选新生代收集器
- Parallel Scavenge 收集器也是一个使用复制算法、多线程、工作于新生代的垃圾收集器,和 ParNew 收集器不同的是,Parallel Scavenge 的目标是达到一个可控制的吞吐量(吞吐量 = 运行用户代码时间 / (运行用户代码时间+垃圾收集时间)),所以更适合做后台运算等不需要太多用户交互的任务
老年代收集器
- Serial Old 是工作于老年代的单线程收集器,主要给 Client 模式下的虚拟机使用。如果在 Server 模式下,它还有两大用途:一是在 JDK 1.5 及之前的版本中与 Parallel Scavenge 配合使用;另一种是作为 CMS 收集器的后备预案,在并发收集发生 Concurrent Mode Failure 时使用
- Parallel Old 是相对于 Parallel Scavenge 收集器的老年代版本,使用多线程和标记整理法,这两者的组合由于都是多线程收集器,真正实现了「吞吐量优先」的目标
- CMS 收集器是以实现最短 STW 时间为目标的收集器,如果应用很重视服务的响应速度,希望给用户最好的体验,则 CMS 收集器是个很不错的选择!CMS 虽然工作于老年代,但采用的是标记清除法
G1(Garbage First) 收集器
G1 收集器是面向服务端的垃圾收集器,被称为驾驭一切的垃圾回收器,主要有以下几个特点
- 像 CMS 收集器一样,能与应用程序线程并发执行
- 整理空闲空间更快
- 需要 GC 停顿时间更好预测
- 不会像 CMS 那样牺牲大量的吞吐性能
- 不需要更大的 Java Heap
为什么 G1 能建立可预测的停顿模型呢?主要原因在于 G1 对堆空间的分配与传统的垃圾收集器不一样。G1 各代的存储地址不是连续的,每一代都使用了 n 个不连续的大小相同的 Region,每个 Region 占有一块连续的虚拟内存地址,如图所示:
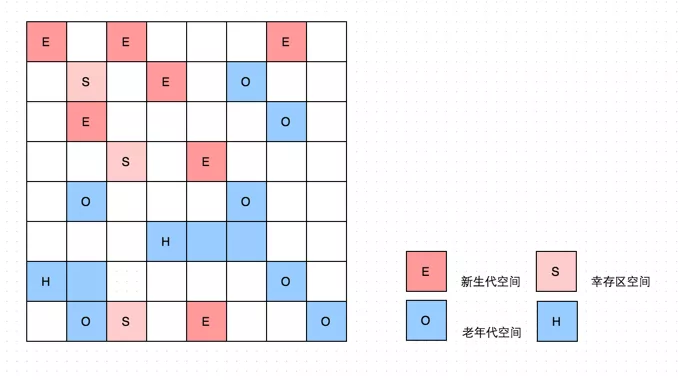
除了和传统的新老生代、幸存区的空间区别,Region还多了一个 H,它代表 Humongous,这表示这些 Region 存储的是巨大对象(humongous object,H-obj),即大小大于等于 region 一半的对象,这样超大对象就直接分配到了老年代,防止了反复拷贝移动。那么 G1 分配成这样有啥好处呢?
传统的收集器如果发生 Full GC 是对整个堆进行全区域的垃圾收集,而分配成各个 Region 的话,方便 G1 跟踪各个 Region 里垃圾堆积的价值大小(回收所获得的空间大小及回收所需经验值),这样根据价值大小维护一个优先列表,根据允许的收集时间,优先收集回收价值最大的 Region,也就避免了整个老年代的回收,也就减少了 STW 造成的停顿时间。同时由于只收集部分 Region,就做到了 STW 时间的可控。
总结
在生产环境中我们要根据不同的场景来选择垃圾收集器组合
如果是运行在桌面环境处于 Client 模式的,则用 Serial + Serial Old 收集器绰绰有余
如果需要响应时间快,用户体验好的,则用 ParNew + CMS 的搭配模式
即使是号称是「驾驭一切」的 G1,也需要根据吞吐量等要求适当调整相应的 JVM 参数
没有最牛的技术,只有最合适的使用场景