布隆过滤器
布隆过滤器(Bloom Filter)是由Howard Bloom在1970年提出的一种比较巧妙的概率型数据结构,它可以告诉你某种东西一定不存在或者可能存在。当布隆过滤器说,某种东西存在时,这种东西可能不存在;当布隆过滤器说,某种东西不存在时,那么这种东西一定不存在。
布隆过滤器相对于Set、Map 等数据结构来说,它可以更高效地插入和查询,并且占用空间更少,它也有缺点,就是判断某种东西是否存在时,可能会被误判。但是只要参数设置的合理,它的精确度也可以控制的相对精确,只会有小小的误判概率。
Redis中布隆过滤器的数据结构就是一个很大的位数组和几个不一样的无偏哈希函数(能把元素的哈希值算得比较平均,能让元素被哈希到位数组中的位置比较随机)。如下图,A、B、C就是三个这样的哈希函数,分别对“OneMoreStudy”和“万猫学社”这两个元素进行哈希,位数组的对应位置则被设置为1:
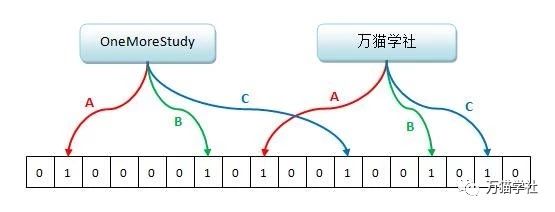
向布隆过滤器中添加元素时,会使用多个无偏哈希函数对元素进行哈希,算出一个整数索引值,然后对位数组长度进行取模运算得到一个位置,每个无偏哈希函数都会得到一个不同的位置。再把位数组的这几个位置都设置为1,这就完成了bf.add命令的操作。
向布隆过滤器查询元素是否存在时,和添加元素一样,也会把哈希的几个位置算出来,然后看看位数组中对应的几个位置是否都为1,只要有一个位为0,那么就说明布隆过滤器里不存在这个元素。如果这几个位置都为1,并不能完全说明这个元素就一定存在其中,有可能这些位置为1是因为其他元素的存在,这就是布隆过滤器会出现误判的原因。
安装(待校验)
之前的布隆过滤器可以使用Redis中的位图操作实现,直到Redis4.0版本提供了插件功能,Redis官方提供的布隆过滤器才正式登场。布隆过滤器作为一个插件加载到Redis Server中,就会给Redis提供了强大的布隆去重功能。
插件安装过程如下:
-
下载
到官网找到最新的包下载即可
[root@redis]# wget https://github.com/RedisLabsModules/rebloom/archive/v1.1.1.tar.gz -
安装
解压并安装,生成so文件
[root@redis]# tar -zxvf v1.1.1.tar.gz [root@redis]# cd redisbloom-1.1.1/ [root@redisbloom-1.1.1]# make [root@redisbloom-1.1.1]# ls contrib Dockerfile docs LICENSE Makefile mkdocs.yml ramp.yml README.md rebloom.so src tests -
配置
[root@redis]# vim redis.conf #####################MODULES#################### # Load modules at startup. If the server is not able to load modules # it will abort. It is possible to use multiple loadmodule directives. loadmodule /usr/local/redis/redisbloom-1.1.1/rebloom.so -
启动
[root@redis]# redis-server redis.conf -
测试
127.0.0.1:6379> bf.add users user2 (integer) 1 127.0.0.1:6379> bf.exists users user2 (integer) 1 127.0.0.1:6379> bf.exists users user3 (integer) 0
基本使用
在Redis中,布隆过滤器有两个基本命令,分别是:
- bf.add:添加元素到布隆过滤器中,类似于集合的sadd命令,不过bf.add命令只能一次添加一个元素,如果想一次添加多个元素,可以使用bf.madd命令。
- bf.exists:判断某个元素是否在过滤器中,类似于集合的sismember命令,不过bf.exists命令只能一次查询一个元素,如果想一次查询多个元素,可以使用bf.mexists命令。
比如:
> bf.add one-more-filter fans1
(integer) 1
> bf.add one-more-filter fans2
(integer) 1
> bf.add one-more-filter fans3
(integer) 1
> bf.exists one-more-filter fans1
(integer) 1
> bf.exists one-more-filter fans2
(integer) 1
> bf.exists one-more-filter fans3
(integer) 1
> bf.exists one-more-filter fans4
(integer) 0
> bf.madd one-more-filter fans4 fans5 fans6
1) (integer) 1
2) (integer) 1
3) (integer) 1
> bf.mexists one-more-filter fans4 fans5 fans6 fans7
1) (integer) 1
2) (integer) 1
3) (integer) 1
4) (integer) 0
上面的例子中,没有发现误判的情况,是因为元素数量比较少。当元素比较多时,可能就会发生误判,怎么才能减少误判呢?
高级使用
上面的例子中使用的布隆过滤器只是默认参数的布隆过滤器,它在我们第一次使用bf.add命令时自动创建的。Redis还提供了自定义参数的布隆过滤器,想要尽量减少布隆过滤器的误判,就要设置合理的参数。
在使用bf.add命令添加元素之前,使用bf.reserve命令创建一个自定义的布隆过滤器。bf.reserve命令有三个参数,分别是:
- key:键
- error_rate:期望错误率,期望错误率越低,需要的空间就越大。
- capacity:初始容量,当实际元素的数量超过这个初始化容量时,误判率上升。
比如:
> bf.reserve one-more-filter 0.0001 1000000
OK
如果对应的key已经存在时,在执行bf.reserve命令就会报错。如果不使用bf.reserve命令创建,而是使用Redis自动创建的布隆过滤器,默认的error_rate是 0.01,capacity是 100。
布隆过滤器的error_rate越小,需要的存储空间就越大,对于不需要过于精确的场景,error_rate设置稍大一点也可以。布隆过滤器的capacity设置的过大,会浪费存储空间,设置的过小,就会影响准确率,所以在使用之前一定要尽可能地精确估计好元素数量,还需要加上一定的冗余空间以避免实际元素可能会意外高出设置值很多。总之,error_rate和 capacity都需要设置一个合适的数值。
代码实现
- 引入依赖 ```
2. 判断是否不存在
@Test public void test3() { setJedisPool(); Client client = new Client(jedisPool); jedisPool.getResource().del(“book”); for (int i = 0; i < 10000; i++) { String book = “book” + i; client.add(“book”, book); boolean ret = client.exists(“book”, book); // 判断自己见过的,没有出现误判 if (!ret) { System.out.println(i); } } jedisPool.close(); } ```
布隆过滤器的应用
解决缓存穿透的问题
一般情况下,先查询缓存是否有该条数据,缓存中没有时,再查询数据库。当数据库也不存在该条数据时,每次查询都要访问数据库,这就是缓存穿透。缓存穿透带来的问题是,当有大量请求查询数据库不存在的数据时,就会给数据库带来压力,甚至会拖垮数据库。
可以使用布隆过滤器解决缓存穿透的问题,把已存在数据的key存在布隆过滤器中。当有新的请求时,先到布隆过滤器中查询是否存在,如果不存在该条数据直接返回;如果存在该条数据再查询缓存查询数据库。
黑名单校验
发现存在黑名单中的,就执行特定操作。比如:识别垃圾邮件,只要是邮箱在黑名单中的邮件,就识别为垃圾邮件。假设黑名单的数量是数以亿计的,存放起来就是非常耗费存储空间的,布隆过滤器则是一个较好的解决方案。把所有黑名单都放在布隆过滤器中,再收到邮件时,判断邮件地址是否在布隆过滤器中即可。
给用户推荐新闻,避免重复推送
当用户看过的新闻,肯定会被过滤掉,对于没有看多的新闻,可能会过滤极少的一部分(误判),但是绝大部分都可以准确识别。这样可以完全保证推送给用户的新闻都是无重复的。